

2020.06.25 |
|---|
MaxDiffのスコア計算ロジックを教えて下さい。
MaxDiffはベスト・ワースト・スケーリングと呼ばれます。最も単純な解析方法としては、各呈示アイテムごとにベストで選ばれた件数からワーストで選ばれた件数を引いたものがそのアイテムのカウントスコアになります。
さらに詳細な方法としては、個人別あるいは全体で、ベストで選ばれたアイテムのスコア、ワーストで選ばれたアイテムのスコアをロジット分析で算出し、その差を各アイテムのスコアとするものです。
もう少し高度な方法では、個人レベルでロジット分析を行う方法があります。以下のようなレイアウトでデータを作成します。この例ではID=1の回答者の1人分のデータです。A~Fまで6つのアイテムを評価しています。
Taskが1問分、Setは1問分に呈示されたアイテムを表しています。Setの内容はA~Fに1/0のビットを立てること(ダミーコード)で表しています。この例では1問に3つのアイテムが呈示されています。
Choiceは呈示された3つのアイテムの内、どれが選ばれたのかをやはり1/0で表しています。1が立っている行が選択されたアイテムを表しています。
Taskの中にSetが2つあるのは1つ目のSet(例えば行1~行3)がベスト用、2つ目のSet(例えば行4~行6)がワースト用となります。
因みに1問目はC、D、Eの3つが呈示され、行1に1が立っているのでCがベストで選ばれ、Eがワーストで選ばれたことになります。2つ目のSet(例えば行4~行6)はアイテムを表すビットが「-1」となっています。これにより回帰分析の際の係数はSet1に対して、正負逆の値となります。つまりベストはプラス、ワーストはマイナスとなります。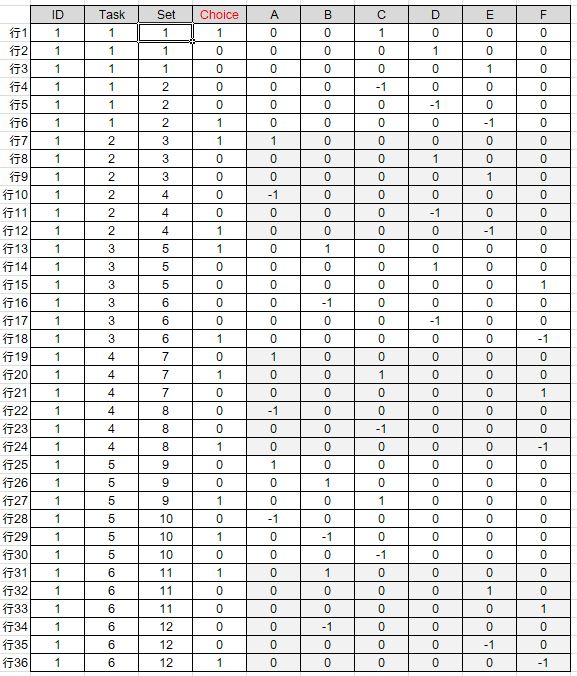
このデータを個人単位レベルでA~Eを説明変数、Choiceを目的変数としてロジット(Individual-level-logit)分析等回帰分析を行うと各アイテムごとに「ベスト-ワースト=スコア」が求まるというのが基本的な理屈です。
Rによる実施の解説がありましたのでリンクをご案内いたします。
https://docs.displayr.com/wiki/Analyzing_MaxDiff_Using_Standard_Logit_Models_Using_R
個人単位レベルでのロジットの場合、アイテム呈示数を一人あたり各アイテム4回以上呈示した方が良いとの報告がありますので、やや質問数が増えることになります。回答負荷を下げるため質問数を絞った場合で個人レベルでの解析を求める場合は階層ベイズ等のアプローチが必要になります。
